Unsupervised Learning
Learning with no labels!
K-Means: Cluster data into k clusters
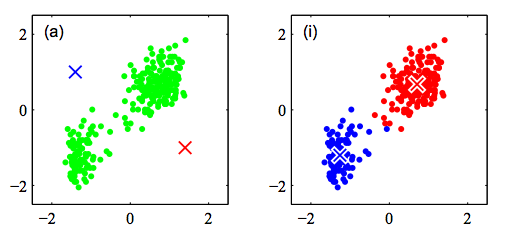
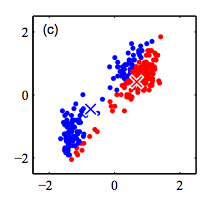
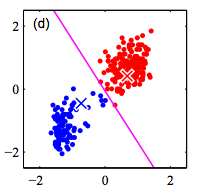
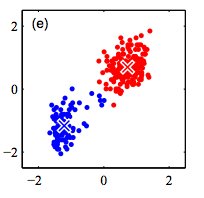
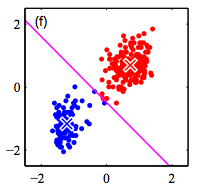
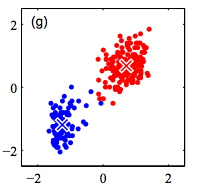
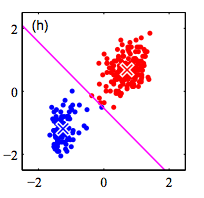
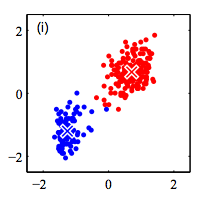
K-Means Algorithm
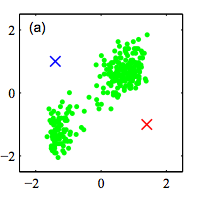
Step 1: Randomly initialize k clusters ($\mu_{k}$)
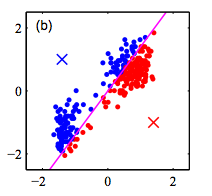
Step 2: Fix the cluster centers, and assign points to clusters
Step 3: Fix the cluster membership, and update cluster centers
Repeat steps 2 and 3 until convergence/stopping criteria met
How to pick k?
K is a hyperparameter
Prior knowledge
Visualize your data (if possible)
NOTE: If let k increase without penalty, error will always decrease
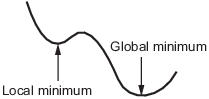
Global vs. Local Optima
K-Means guarantees a local optima if run to convergence
K-Means++
Better cluster initialization
Shown to converge more quickly than K-Means
Instead of randomly initializing the k clusters, tries to spread out the clusters
The rest of the algorithm is same as K-Means
Spark implements a parallel version of cluster initialization called K-Means||
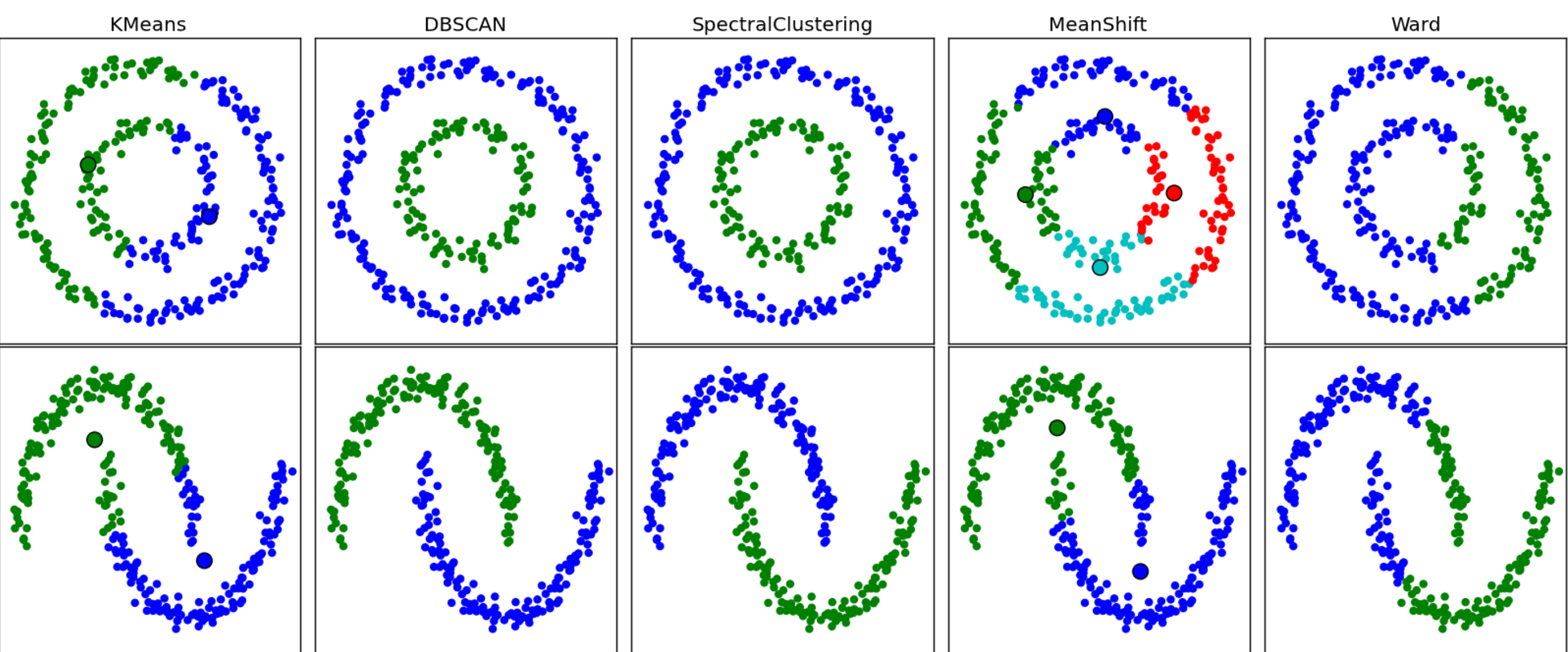
Clustering Techniques